ぬるさくで学んだ基礎を生かして、アプリを作ってみよう!
ぬるさくの学習はこちら
参考はこちら
Kaggleの説明もこちら
そしてKaggleの入門用コンペ
Titanic: Machine Learning from Disaster
https://www.kaggle.com/c/titanic
最初にプロジェクト用のディレクトリ(例:titanic)を作成し、その中にdatasetフォルダを作成して、ダウンロードしたデータを配置。
さらにworkspaceディレクトリも作成。
Anaconda-Navigatorを起動
Notebookを起動
プロジェクト用のディレクトリのworkspaceに移動
New > Python 3
そうすると
import pandas as pd
import numpy as np
train = pd.read_csv("../dataset/train.csv")
test = pd.read_csv("../dataset/test.csv")で行ける。
「データセットの欠損の確認」のスクリプトは、そのまま貼り付けるとインデントが効いていないので注意。
「文字の数字への置き換え」のところでエラー発生。
train["Sex"][train["Sex"] == "male"] = 0
train["Sex"][train["Sex"] == "female"] = 1
train["Embarked"][train["Embarked"] == "S" ] = 0
train["Embarked"][train["Embarked"] == "C" ] = 1
train["Embarked"][train["Embarked"] == "Q"] = 2anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
"""Entry point for launching an IPython kernel.ところが、
train[train[“Sex”] == “male”]
で見てみるとデータが表示されない。
もう一度、
train.head()
してみると、データが置き換わっている。warningだからやってはくれるのか・・・
その後は順調に進み、提出もOK!これだけで嬉しくなりますね。
ちなみに、二番目提出の状態で、
# 可視化ライブラリのインポート
import matplotlib.pyplot as plt
import seaborn as sns
# matplotlib による可視化
plt.hist(my_solution_tree_two["Survived"], bins=10 )とやると、こんな表示。
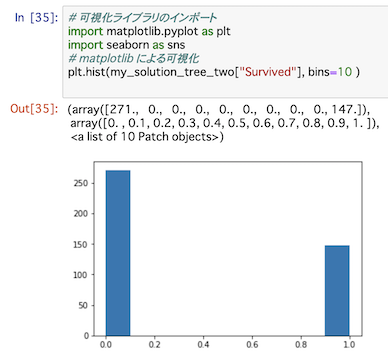
これじゃ何も面白くない・・・
ということでちょっと追加
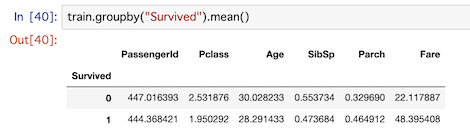
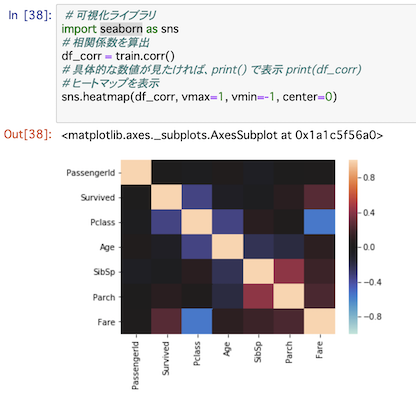
これを元に、もう少し研究してみたいと思います。
本買うとしたら何が良いのですかね。
この本は評判良さそうですが、それ以上に、この本のAmazonのページの情報が濃い!
